一、读取arff文件
1、使用scipy.io中arff读取文件
1 | import pandas as pd |
2、转化为DataFrame
1 | df =pd.DataFrame(data) |
3、使用LabelEncoder对类别Class进行编码
1 | from sklearn.preprocessing import LabelEncoder |
4、使用sns与plt绘制不同类别的数量
1 | import seaborn as sns |
二、针对空值填补
1、查找空值
1 | DataDF.isnull().sum().sort_values(ascending=False) |
2、删除有缺失值的行或者列
1 | '''移除行或列"''' |
3、常规填补法
均值
1 | all_features.Embarked = all_features.Embarked.fillna(all_features.Embarked.mean()) |
最近邻,前后,在时间序列分析中比较常见
1 | print(DataDF.UnitPrice.fillna(method='ffill')) # 前向后填充 |
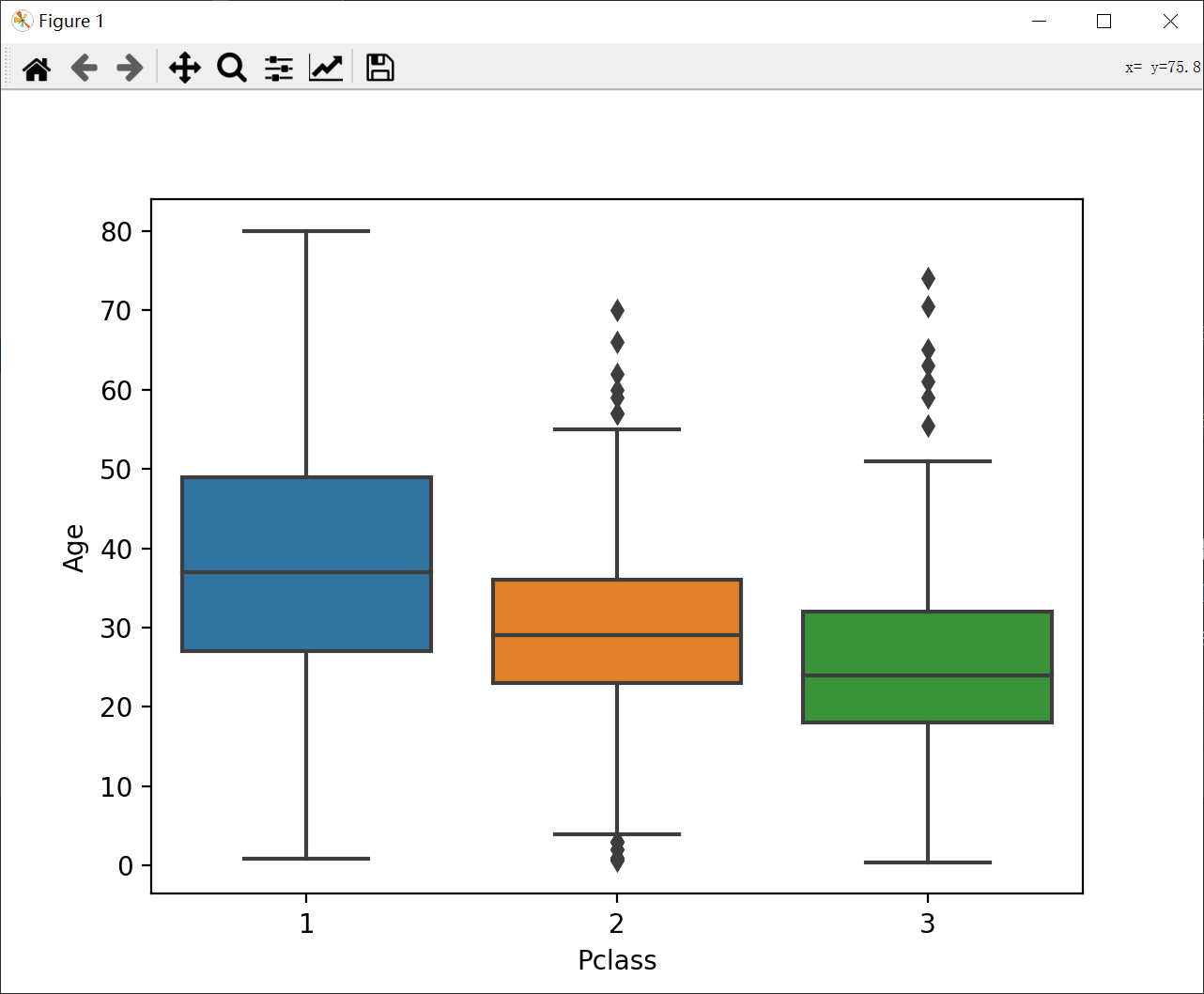
4、使用与之相关的属性,相近的求均值填补
1 | sns.boxplot(x = train_data["Pclass"], y = train_data["Age"])plt.show() |
1 | ''' |
5、具体分析
1 | df_data['Title'] = df_data.Name.str.extract(' ([A-Za-z]+)\.', expand=False) |
| Title | Capt | Col | Countess | Don | Dona | Dr | Jonkheer | Lady | Major | Master | Miss | Mlle | Mme | Mr | Mrs | Ms | Rev | Sir |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sex | ||||||||||||||||||
| female | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 260 | 2 | 1 | 0 | 187 | 2 | 0 | 0 |
| male | 1 | 4 | 0 | 1 | 0 | 7 | 1 | 0 | 2 | 61 | 0 | 0 | 0 | 757 | 0 | 0 | 8 | 1 |
1 | """ |
三、文字类转化为数字
1、使用LabelEncoder对特征进行编码
1 | from sklearn.preprocessing import LabelEncoder |
2、直接替换
若该属性只有几类,可直接替换
1 | train_data.Embarked=train_data.Embarked.map({'S':0, 'C':1, 'Q':2}) |
或
1 | all_features.Sex.replace('male', 1, inplace=True) |
3、one-hot编码
四、缩放和规范化
在缩放中更改数据的范围,
而在规范化方面,更改数据分布的形状。
- in scaling, you’re changing the range of your data, while
- in normalization, you’re changing the shape of the distribution of your data.
缩放:
1 | original_goal_data = pd.DataFrame(kickstarters_2017.goal) |
规范化:
1 | original_pledged = pd.DataFrame(kickstarters_2017.pledged) |
五、日期处理
1、将日期规范化后存入dete_parsed列中
1 | landslides['date_parsed'] = pd.to_datetime(landslides['date'], format="%m/%d/%Y") |
注意!format中%Y尽量用大写
2、从时间属性值获取日期/月份/年份
1 | day_of_month_earthquakes = earthquakes['date_parsed'].dt.day |
六、数据统一
对于同一个属性的同一个值,由于输入时空格,大小写等原因,造成不一致的问题
1、提取出属性中出现的值,并使用unique()获取互不相同的值
1 | countries = professors['Country'].unique() |
2、删除头尾空格,把所有大写字符转化为小写
1 | professors['Country'] = professors['Country'].str.lower() |
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
Python lower() 方法转换字符串中所有大写字符为小写。
3、模糊处理
1 | matches = fuzzywuzzy.process.extract("usa", countries, limit=10, scorer=fuzzywuzzy.fuzz.token_sort_ratio) |
1 | def replace_matches_in_column(df, column, string_to_match, min_ratio = 47): |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 折花入酒blog!